- In the common work ethic, your work is not simply valued by its results, but by your industrious efforts. If your work is automated, despite producing exactly the same results, we do not call it work and consequently you should not receive the same compensation.
- Disclosing your automation scripts likely does not come to the benefit of the employee, but instead to that of the employer and stakeholders of the company. In that sense, automation often fails to promote well-being for workers, which is (and should be) one of its main promises.
- Friends/acquaintances can write a post on a topic reflecting a shared interest. My interests are very broad, so finding such a common interest should not be too hard.
- I will publish the post, unless I consider it completely unsuitable to be associated with my name.
- My role in the process ranges somewhere between a minimal form of redaction, and full cooperation in writing the post.
- In return, each contributor gets their own home page on this domain. This homepage lists all their contributions, and apart from that they are free to do with it as they please. (Technically, this amounts to giving them their own branch on the Github repo of this site)
- ~p -> (p -> q)
- (~p /\ p) -> q
- q -> (p -> q).
- ~(p /\ ~q)
- ~p / ~~q (DeMorgan’s law)
- ~p / q
- ~(p -> q) -> (p /\ ~q).
- ~(p -> q)
- ~(~p / q) (DeMorgan’s Law)
- (~~p /\ ~q) (Using ~~p entails p)
- p /\ ~q
The original paper on PageRank that fundamentally changed how the web looks today was rejected by the SIGIR 1998 conference.
In Appendix A of the paper mentioned above the authors discuss the dangers of advertising for search machines.
Ecological speech often has a theistic element: the idea that the whole is always greater than the sum of its parts. This whole is then usually called “Nature”, preferably with a capital N.
But does this theistic admiration of the whole not also imply that the parts are to some extent expendable? Take for example James Lovelocks idea of ‘Gaia’. Thinking of the whole as greater than its parts contributes some sort of “agency” to this whole, giving it relative independence from its constituent components. When seeing “the bigger picture” the extinction of species can be conceptualized as a mere shift in components; humans might go extinct, but Nature will survive and find some new balance. Perhaps the “agency” of the whole can in that sense be characterized as the act of balancing out. Insofar as this balancing is only visible from the perspective of the whole (which is non-attainable “from within”), it seems destructive and chaotic insofar as things like extinction are part of the job. In any case the whole is here somehow conceived as something grandiose. “Nature” is now given as an example, but according to Morton any entity would suffice, only the scale differs. Humans, cars, butterflies, name it, my laptop. The side-effect of this view is that parts are in principle considered to be expendable components, subjected to this grandiose whole. But is this the right meaning of: “the whole is always greater than the sum of its parts”?
Morton’s dilemma: he does not want to simply consider entities as subjected to their whole (whatever that may be), but at the same time he definitely is a holist in the sense that he does not believe entities can be reduced to their parts. In other words, if he wants to keep calling himself a holist, what does his holism then precisely mean?
The perverse twist: what if the whole is less than the sum of its parts?
This is an intuitive truth for object-oriented ontology according to Morton. (Ontology for Morton refers to the study of how things exist, not the study of what exists. The latter Morton calls “object-policing.” This also resonates with the phrase “The how is the what” that Morton kept repeating during his public lecture in Nijmegen; a basic phenomenological insight that he cleverly adapted.) Morton’s object-oriented ontology says: if something exists, it exists in the same manner as everything else that exists. That is, all existing objects have a gap between how they are and how they appear. This gap irreducible and yet transcendental: appearance and being, despite the gap between them, inextricably go together,
Morton takes his hand as an example of an object. The hand is one whole, but when considering each of the fingers, that are part of the hand, they are all also themselves considered as a whole, not simply as a part. This is where Morton makes his perverse inversion of holism. Conclusion: There is more “whole” in the sum of the parts than there is in the “whole” of the hand… 5x whole > 1x whole. The whole of the hand is less than the parts.
This subversive conceptual reasoning that raises suspicion about the idea that the whole would be greater than the parts, has a political dimension for Morton insofar as a strong belief in the “greater good” of the whole can lead to justification of violence. Ontology, Morton likes to say, is political. And it should never justify subjection to a whole.
The mantra of object oriented ontology is that everything is an object, and than everything exists in the same way. It is therefore incompatible with a more classical idea of holism, because that classical conception contributes to the whole a different way of being. In this classical sense, that the whole is more than its parts could also mean that ontologically speaking the parts exist to a lesser degree, that they are “lower” in being. Conversely, when Morton says that the whole is less than its parts, this “less” is not intended to imply an ontological difference in the way of being, but instead a quite radical egality: if everything exists fundamentally in the same manner, then the “more” in holism almost (or completely?) becomes a numerical notion: there are simply more parts than wholes.
The latter insight is also why object-oriented ontology and ecological thought seem to be natural allies: both human and non-human beings, of whatever kind, exist in the same way. Nature in this sense is thus not something “other” than the sphere of human existence (the term “sphere” is already unfavorable for Morton’s thought because it seems to imply something that is closed off).
We as humans exist inside various wholes of differing scales but are not subjected to them, e.g. the biosphere, or liberalism or capitalism, which manifests itself physically in various forms around the globe (they are all also objects, nothing more and nothing less). However, we should be careful with talking about increasingly bigger entities, such as the ecological crisis, in what Morton calls a “my god is bigger than yours competition”, again referring to the theistic element of holism that has as a side-effect that we feel overwhelmed by and subjected to the whole.
Instead, Morton suggests, we should try to redirect our attention away from those big entities to smaller ones, because although they are physically big, they are ontologically smaller according to his perverse holism. When we walk in a forest, we encounter flora and fauna, trees, deer, fungi, but we never encounter “Nature”. Accordingly, Morton’s insights concerning holism should change how we can meaningfully practice things like nature preservation.
Getting a grip on programmer jargon
Joran started a programming traineeship after graduating from a theater education. I asked him to write something about how he experiences this transition - Edwin
I’ve been dabbling in programming for a while now, on account of the fact that I have recently started working in it full-time. I reckoned I could be able to write an article for this website because of that, so I tried to come up with something clever to discuss until I came to my senses and realised I’m a total newb. Whatever computer related revelation I’ve had over the past few months would be somewhat out of place on Edwin’s site full of computer cleverness.
For example, you might know that
 is the button that turns things on.
Fascinating stuff.
But then I had this revelation when I learned that that button is a combination of a 1 and a 0, which I had no clue about!
This experience of being clueless and amazed about the smallest things is however actually quite representative of my experience as a new programmer.
It’s a pretty crazy experience being thrown head-first into the world of computers with no relevant knowledge or previous experience whatsoever, so surely there’s something interesting to be found there. Let’s see…
is the button that turns things on.
Fascinating stuff.
But then I had this revelation when I learned that that button is a combination of a 1 and a 0, which I had no clue about!
This experience of being clueless and amazed about the smallest things is however actually quite representative of my experience as a new programmer.
It’s a pretty crazy experience being thrown head-first into the world of computers with no relevant knowledge or previous experience whatsoever, so surely there’s something interesting to be found there. Let’s see…
The main thing I noticed as a novice programmer is just how much terminology you have to get familiar with simply to be able to slightly follow what is going on. Of course, whenever you enter a new area of work, having to learn some new jargon is to be expected, but even when taking this into account I think the world of IT is pretty insane.
The first wave of new words consists of a plethora of technical terms, most of which I initially thought I understood. It turned out I really didn’t… Words like class, interface, router, server, browser, directory, method, parameter, garbage collection, integer, bootstrap, long, object, image, short and double… Then one needs to know a few abbreviations like CPU, JVM, OO, UI, HTML, CSS, XML, YAML, API, WAR, JAR, PHP, SQL, MVC, JSON, DOD, DOR, ORM, POD, MVP, GNU, SAP, PO, HANA, ABAP, DSP, MDBC, JDBC, TDD, SOAP, REST, WADL and HTTP. And to top it all off there’s a never-ending cascade of names: Jenkins, GitHub, Java, JavaScript, Python, Oracle, RedHat, Openshift, Spring, Slack, Sun, Eclipse, IntelliJ, Ansible, Angular, ThymeLeaf, Gradle, Maven, KeyCloak, Citrix, OnePassWord, iTerm, RaspBerryPi, Arduino, Kobolt, Unix, Hibernate, JUnit, Mockito, JHipster, Javalin, Jackson, Lombok and so on and so forth… and now imagine needing all of this to convey some crucial bit of information to you!
All this basically amounts to a sort of dialect that is incomprehensible to anyone who isn’t in the know. I realise that to an experienced programmer this probably reads like someone complaining about such unfathomable words like apple, window and tree and yes, those were the first three things I saw when I looked around, but I have to spend every day laboriously googling all the enigmatic words I hear just to try and get up to speed. Oh yeah, they also mention the Architect a lot, which makes me feel like I’m in the Matrix, it’s great.
Of course, getting to know so many new concepts is not just tiring; the most interesting technical term I’ve heard over the last few months is slave. Every once in a while someone unthinkingly uses it and is then corrected because you’re supposed to call it an agent or a helper now. At first this baffled me. The master/slave terminology is sometimes used when talking about a system in which one device unilaterally controls other devices. So whenever someone mentions it, they’re obviously referring to such a mindless device instead of to an actual slave, so why the sensitivity? The other day though, I stumbled upon a clip from Last Week Tonight that shed some light on the matter: in it John Oliver mocks the voice-over from a very old video about robots for repeatedly calling them mechanical slaves by saying: “Slaves, slaves, slaves! Oh how I have missed them! If you close your eyes you can forget that they’re mechanical…”
I suddenly understood why it might be a good idea to ditch the term. I do think it’s an intriguing phenomenon though… Is it just that we want to distance ourselves from the term in and of itself or might we also be crossing a different line, albeit inadvertently? That is, are we entering an era in which we feel increasingly uneasy about calling machines slaves because they seem increasingly human? Most machines we use today can still fairly be treated as nothing but objects, but could you for example say the same about Alexa or Siri? As the machines we use are getting more intelligent and more like living beings everyone in society is at some point going to have to change the way they regard them and I like to believe that the mechanical slave discussion is an early sign of the beginning of that process. Of course, some people have already been aware of such developments for a long time and they have been discussing them at length, for example on webpages not dissimilar to this one. I’m curious to see where it will take us. For now I’ll just continue learning the words so I can discover new layers of meaning and gather more insights into the magical world of programming.
Joran.
P.S. This is a podcast I found on the origin of the term robot. If anyone’s interested.
Automation and the ethics of work
For a working group I give at the Radboud University, students were asked to read “The Coders Programming Themselves Out of a Job”. This article discusses the ethical considerations of people automating their own jobs, either partly or completely. What are these considerations, and how do they relate to common work ethic?
On the one hand, these people fulfill their job description to perfection through the scripts they wrote. One could applaud this clever increase in efficiency and the accompanying consistent performance. Moreover, freed up time can of course be well-spent, whether it is on family life or on learning new professional skills (that might also be valuable for your employer in the end!). On the other hand, as these people literally program themselves out of a job, they end up spending their time freely on non-work related activities while being on a payroll, sometimes for years on end. The question then is whether they are cheating, and deceiving their employer? And should they notify your employer of the fact that they are no longer spending time on your job? Such disclosure is not without risk. Many contracts treat everything developed under company time as their intellectual property, so after disclosure of the automation of your own job a company might not only claim the script as theirs, but might also dissolve your job and potentially those of your peers as well.
We could say that these clever programmers participate in a form of grassroots automation that emerges bottom-up rather than being issued top-down by some executive in a reorganization. This creates a slightly different set of issues than the more straightforward story of “my job got replaced by a machine”. The difference is that in the latter case the process of automation is publicly evangelized, whereas what makes the case of self-automation poignant is the ethical question of disclosure: Should I tell others, or my employer? And should I share my scripts? And why, or why not? These considerations concerning work automation only become more relevant as AI technologies become more widely available.
Another relevant aspect is that in the case of automation across the board, the beneficiary is usually the employer, whereas in this mode of grassroots self-automation, it is the employee that reaps the benefits. But if these clever employees get the job done more efficiently, why then do people often keep their self-automation silent, and feel that somehow what they are doing is ethically wrong or ambiguous at the least? The article states:
Even if a program impeccably performs their job, many feel that automation for one’s own benefit is wrong. That human labor is inherently virtuous — and that employees should always maximize productivity for their employers — is more deeply coded into American work culture than any automation script could be.
This resonates deeply with me, as I too am one of those people that attributes a lot of value to work. And many people in my environment are plagued by a constant sense of guilt: have we worked enough, shouldn’t we work more?
Through above-mentioned article, I came across the essay “In Praise of Idleness” of Bertrand Russell, written in 1932, but even more relevant today I would say. The sermon of technological automation is that the same amount of work can be done in let’s say half the time, and that this should lead to an increase in wealth and happiness for everyone. But instead of everyone then working half working days, a part of the population (those on the “right side” of automation) only seem to make longer days, whereas others become unemployed and see their life quality plunging (those made “redundant” by automation). If automation only contributes to the good of employers, then technology will only increase social divides along new lines, between “normal” workers and the those that are tech-savvy.
In that context, consider how relevant these words from 1932 sound:
If at the end of the War the scientific organization which had been created in order to liberate men for fighting and munition work had been preserved, and the hours of work had been cut down to four, all would have been well. Instead of that, the old chaos was restored, those whose work was demanded were made to work long hours, and the rest were left to starve as unemployed. Why? Because work is a duty, and a man should not receive wages in proportion to what he has produced, but in proportion to his virtue as exemplified by his industry. This is the morality of the Slave State, applied in circumstances totally unlike those in which it arose.
And:
Modern technic has made it possible for leisure, within limits, to be not the prerogative of small privileged classes, but a right evenly distributed throughout the community. The morality of work is the morality of slaves, and the modern world has no need of slavery.
What we should then think about is how technology and automation can increase the quality of life in a distributed and democratic manner. From this perspective, we can thus understand the hesitance to disclose self-automation towards one’s employer due to two reasons:
What is cool about the grassroots approach of self-automation is that it makes technology follow through on its promises to allow shorter working days and more happiness, e.g. by having a half working day with more time to spend with your family. How can we be against that? And why do many people, including me, associate this reduction of work with a loss of status and ambition? Much to think about. The main challenge for the future, and I think one that is extremely relevant in our contemporary society, is to distribute these advantages amongst peers in such a way that it comes to the benefit of all by taking a load of our shoulders.
Or in the words of Russel:
a great deal of harm is being done in the modern world by the belief in the virtuousness of work, and that the road to happiness and prosperity lies in an organized diminution of work.
N.B. The question the students had to answer was: a) In what ways could you automate your work as a student, and b) would you feel ethically obliged to disclose this automation to your study program? I had a lot of fun grading their work.
What is the purpose of this website?
I largely quit social media because it transformed from being something that helps me keep in touch with people and that stimulates social interaction, to an endless stream of promoted clickbait content. The little “real” personal content that made it to my feed, was usually dull and did not facilitate any interesting conversations. With the creation of this website I’m trying to take control of my online identity, making this domain a main hub for various dispersed identities, somewhat along the lines of these principles.
Being free to do with this website what I want in a way that is meaningful for me, gives me joy. In addition, this website really is personal because I built it myself, which comes with a sense of pride (in the positive sense of the word). This is my first website, and I had no idea what I was doing when I started out. I had never written any html or css, but with the help of a friend during a nightly Skype-session (during which he fell asleep) I had a very simple one page site online within a few days. It was really, really bad. But it was out there, and it was mine. Over time I kept incrementally improving on it bit by bit, and by now I’ve reached a point where I’m quite content with the websites’ features and its minimalistic look (although I’m constantly fighting the urge to delete almost all css and go barebones). By now, I even find myself stimulating others to make their own personal website, and helping them out in the process. Over the last weeks, I helped my friend and philosopher Boris make his own website. I know that for the average philosopher all hands-on tech stuff is, well… Let’s just say in general they like thinking about technology more than using it. If you keep your website simple enough however, you can learn to maintain it yourself, even if you are a philosopher. Even although it might be a bit rough in the beginning, it will have all the more charm because it is authentic. Especially for academics, sober (or one might say: Spartan) websites have a long history (see for example this article. We need people to make their own websites again to keep the web an interesting and diverse place, and offer some resistance against the boring uniformness of yet another generic Wordpress blog or Facebook page. Boris’ work and thoughts are interesting and deserve a cool website. He published his new website last week, and I’m convinced it’s the beginning of a nice digital journey where a lot will be learned. Check it out here.
Anyways, the bottom-line is that what makes my website personal for me is not only that it contains personal content, but that it facilitates more meaningful interaction with people than so-called “social” media (and that does not mean more interaction). For me, the point of my blog is to help me shape my thoughts on topics of interest, but specifically in such a way that I can involve others in this process. The overarching goal is to enable dialogue and interaction with other people through a sensible digital identity, whether that means reinforcing existing relations or perhaps making new ones. I currently play with the idea to represent some of this dialogue directly on the website itself, by also allowing others to post on my domain, which is in the spirit of my plea that more people should have their own little place on the web. In short, I want to offer digital residence to friends on my domain. I do not yet completely know how this will work out, but my current experimental idea is this:
I made an example of such a homepage here.
As for the content of the blogs, I consider them to be an exercise in imperfection. They are not as unstructured as notes, but neither are they fully developed like articles. They are somewhere in between, more like essays in their original sense: they are attempts, exercises in writing and thinking that do not shy away from incompleteness. It’s yet another reason why I like to think of them in terms of a dialogue: in real conversations answers are not known in advance; they can be confused, open-ended. It is no coincidence that blog writing has such a conversational style. It reflects thinking on-the-way (yes, that is a reference to Heidegger), and in one sense it is a text that ideally does not want to be written down. Its conversational style is a resistance to the suggestion of completeness that accompanies writing, and tries to be spoken language: a voice amongst other voices.
For me personally, perfectionism has in the past prevented me from daring to publish or submit anything. An additional benefit of these blog posts is that they are a good exercise in letting go. I write them as quick as possible and then immediately publish them, to avoid that they stay on the shelf. There is another benefit: I have struggled the last years with formulating the relevance of philosophy. After starting a second university education, I have come to the belief that philosophy is at its best when it does not only engage with other philosophers, but (also) engages with other disciplines, shaping and enriching them from within. I hope that as this blog develops, it will be a testimony to this thought.
Paradoxes of the logical implication
When one starts studying logic one is likely to be surprised by the workings of the so-called material implication, p –> q (if p, then q). Unlike the implication used in natural language, which can for example indicate causation, the material implication has a more restricted meaning. The material implication is true unless p is true and q is false. This is ultimately a matter of definition to resolve ambiguities present in natural language. A very simple and short sentence such as “visiting relatives can be boring” can already have two very different meanings. Either it is boring to visit relatives, or relatives that are visiting can be boring. Logic seeks to resolve such ambiguities by explicitly agreeing on a formal interpretation of symbols.
The meaning of the material implication is reflected in this truth table:
| p | q | p -> q |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
A consequence of this stricter definition of the implication in logic means that sometimes its formal interpretation is at odds with the way implications are interpreted in natural language. This can lead to the experience of a paradox. The part of the material implication that is counter-intuitive to most people is that p -> q is true when p is false, irregardless of whether q is true. This is called a vacuous truth in logic: if p is false, then p -> q is asserting a true property of something that does not occur.
Since the material implication is defined as “it is not the case that p is true and q not” ( ~(p /\ ~q) ), the only way we can show that the implication does not hold is by a counterargument where p holds and q not. However, if p never holds, we are not able to give such an argument and it is said that the implication holds vacuously. The implication then is an “empty truth” that is true because we cannot show it to be false, but that does not convey any information.
Consider an analogue example. If you would say to your father that he is your favourite (biological) father, this would be true. But it is equally true that he is your least favourite father, and these two statements thus do not convey any information about the father (or your attitude towards him). Both statements can be thought of as empty truths: the statements are a comparison with another non-existing father and thus are true “automatically”.
We can show some more statements that are counter-intuitive but hold according to this definition of the material implication (see here). We can see in the above truth table that the material implication is true if p is false. If the expression p is a contradiction, it will always be false. Hence, if we have a contradiction, we can conclude any formula q:
Although this is “logical”, this leads to very weird results when translated to natural language. For example: if it rains and it does not rain, then my cat can fly. This is called ex falso sequitur quod libet. Anything follows from a contradiction.
At the same time, we can also see in the truth table that when q is true, the implication always holds, irregardless of the truth of p. But this also sounds a bit counter-intuitive: if q is true, then any p implies q.
For example, when we say in natural language “if I am sick, then I go to the doctor”, we assume there is a clear (causal) relation between these propositions. The above formula then would say: if I go to the doctor, then it holds that if I’m sick, I go to the doctor. That is clear enough. But logically speaking, it is equally true that “if I go to the doctor, then if I’m not sick, I go to the doctor.” This has a quite different ring to it: people usually do not go to the doctor because they are not sick (unless they are hypochondric).
So far we have that p -> q is always true if p is false, or if q is true. Thus we can rewrite p -> q as ~p / q. This follows pretty directly from the definition of the logical implication, i.e. “it is not the case that p is true and q is not true”:
You can easily see the equivalence of these formula’s as they have the same truth table:
| p | q | ~p | p -> q | ~p / q |
|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 1 | 1 |
We can use this for example to show that if p does not imply q, then p holds and q does not hold.
This is also quite surprising! For example, this could mean: If Edwin eating a lot of cheese does not imply that Edwin lives in the Netherlands, then Edwin eats a lot of cheese but Edwin does not live in the Netherlands.
We can show that the left and right statement are equivalent, for example as such:
Proof:
N.B. ~~p ==> p does not hold in intuistionistic logic.
If you master all of this, you can make (and explain) jokes like these:
Ethics of Autonomous Vehicles: beyond the trolley dilemma
This is a short commentary I wrote in 2017, on Patrick Lin’s “Why Ethics Matters for Autonomous Cars”.
The book Autonomous Driving formulates a set of use cases that serve as a reference point for discussing the technical, legal and social aspects of autonomous driving (Wachenfeld et al. 2016). In addition, Lin sketches scenarios that require ethical choices to be made by autonomous vehicles (AVs). An advantage of this approach is that these scenarios can take the form of thought experiments, which are not obstructed by the fact that as of yet no fully AVs are in use: they nevertheless draw out moral intuitions that are in turn useful for helping us formulate how we expect robots to react in similar situations (Malle 2016, 250). One classical thought experiment in particular, the trolley dilemma, seems to experience a revival in the context of AVs (Lin 2016, Contissa, Lagioia, and Sartor 2017, Nyholm and Smids 2016). However, despite its popularity, I argue that ethical questions concerning AVs go beyond the scope of the original trolley dilemma.
In its classical form, the trolley problem situates an observer near a switch, overlooking a trolley on its way to kill five unsuspecting people working on the tracks. However, using the switch would divert the trolley to kill only one person. The question then is: is it correct for the observant to pull the switch? It is easy to imagine such a trolley problem for AVs, where the “switching” decision has to be made by the AV, and indeed Lin does so (Lin 2016, 78-79). However, whereas usually trolley problems concern the question what is the right choice, in the case of AVs it also includes the underlying question who made the choice and is correspondingly responsible for it.
Two cases sketched in Autonomous Driving, let’s say A and B, are particularly interesting in this regard. Case A concerns fully automated driving with the extension of a human driver that is able to take over drive control at any moment. In Case B, the driving task is performed completely independent of the passenger, which also entails that the passenger cannot take over driving control (Wachenfeld et al. 2016, 19). In case A, the trolley problem arguably maintains its original form: when a human is able to take over control, the switching decision also remains the responsibility of the human driver, but only as long as we ignore the practical issue that the handing over of control to the human driver is unlikely to be fast enough (Lin 2016, 71). In case B however, it cannot in any case simply be the human driver that is responsible for the life-death decision, and thus case B extends beyond the scope of the original trolley problem.
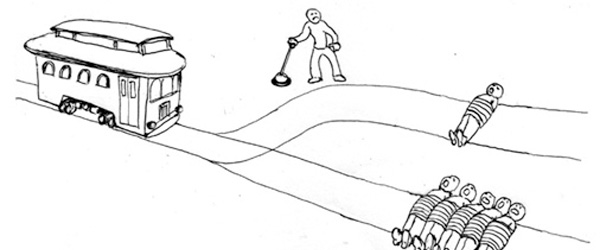
The AV would make such life-death decisions based on programmed algorithms and cost functions. I would say that therefore the real ethical decisions are no longer made split-second, as in the trolley problem, but instead are moved to the design stage where such time-constraints do not apply (Nyholm and Smids 2016, 1280-2). A particular difference with the trolley problem thus is that responsibility for possible deaths is distributed over a set of stakeholders. The possible answer to the question who is to blame has large consequences for example for producers of AVs (vulnerability to lawsuits) or insurance companies (dealing with damage claims). I agree with Lin that regardless of the answer, transparency of the decision-making should be central to AV ethics (Lin 2016, 79).
In that sense, one recent suggestion is particularly interesting as an addition to Lin’s deliberations in the context of the defined use cases. In case B, a way to again involve the user in the design process is to use an ‘ethical knob’ that makes the preference for the survival of passengers or third parties explicit in moral modes ranging from altruistic, to impartial and egoistic (Contissa, Lagioia, and Sartor 2017). These modes determine the “autonomous” decision-making of the AV, but are deliberately set by the user. In this manner, the moral load of using the AV becomes transparent to the user, which in turn may be a decisive factor for quantifying guilt in case of lawsuits and insurance claims. To conclude, in designing AVs robot ethics and machine morality can be connected by fine-tuning the moral competences AVs have with respect to a dynamic set of situations and preferences (cf. Malle 2016).
672 words.
N.B. click here for an alternative solution to the trolley problem.
References ¶
Contissa, Giuseppe, Francesca Lagioia, and Giovanni Sartor. 2017. “The Ethical Knob: ethically-customisable automated vehicles and the law.” Artificial Intelligence and Law 25 (3):365-378. doi: 10.1007/s10506-017-9211-z.
Lin, Patrick. 2016. “Why Ethics Matters for Autonomous Cars.” In Autonomous Driving, edited by Markus Maurer, J. Christian Gerdes, Barbara Lenz and Hermann Winner, 69-82. Springer-Verlag Berlin Heidelberg.
Malle, Bertram F. 2016. “Integrating robot ethics and machine morality: the study and design of moral competence in robots.” Ethics and Information Technology 18 (4):243-256. doi: 10.1007/s10676-015-9367-8.
Nyholm, Sven, and Jilles Smids. 2016. “The Ethics of Accident-Algorithms for Self-Driving Cars: an Applied Trolley Problem?” Ethical Theory and Moral Practice 19 (5):1275-1289. doi: 10.1007/s10677-016-9745-2.
Wachenfeld, Walther, Hermann Winner, J. Christian Gerdes, Barbara Lenz, Markus Maurer, Sven Beiker, Eva Faedrich, and Thomas Winkle. 2016. “Use Cases for Autonomous Driving.” In Autonomous Driving, edited by Markus Maurer, J. Christian Gerdes, Barbara Lenz and Hermann Winner, 9-38. Springer-Verlag Berlin Heidelberg.
Warlike acts in the cyber domain
This CSO article reports on a massive ransomware attack with NonPetya that is estimated by CyberReason research to have costs businesses globally around 1.2 billion dollar.
One paragraph in particular caught my eye:
To complicate matters, having cyber insurance might not cover everyone’s losses. Zurich American Insurance Company refused to pay out a $100 million claim from Mondelez, saying that since the U.S. and other governments labeled the NotPetya attack as an action by the Russian military their claim was excluded under the “hostile or warlike action in time of peace or war” exemption.
You can read the official U.S. press release. What interests me is not just the small letters of insurances policies, although they can have huge financial consequences for companies in this case. Philosophically and politically, the more interesting question is what constitutes an act of war in the cyber domain. In this scenario, insurance money is paid based on whether the cyber attack is considered a warlike act or not. The phrasing “warlike action in time of peace or war” anticipates a difference between such warlike attacks and “actual” war, as these “warlike” acts do not have to take place during war time.
Traditionally, wars occur between two nations that are identifiable. If they play fairly, they can even officially declare war before knocking on someone’s door. It is important that these parties are identifiable, so that they can be held accountable in terms of the Geneva Conventions for example. However, in the case of cyberattacks, there can be significantly more ambiguity concerning the identity of the attacker.
Take for example a well known cyberattack on DigiNotar, a certificate authority in the Netherlands (for public key encryption). Due to a hack fake certificates had been issued, compromising the trustworthiness of DigiNotar certificates, resulting in the removal of these certificates for example from all major browsers. To complicate matters, the Dutch government internally used many DigiNotar issued intermediary certificates that chained up to the Dutch government CA itself (see for example Firefox’ communication about this. The DigiNotar certificates becoming untrusted consequentially threatened to destabilize the Dutch government, as official services such as the tax system and the online ID management system for Dutch citizens (DigID) that is used to access government services threatened to become inaccessible. In other words, the hack was a threat to the stability of the Dutch state. Is this a warlike act? Or is it an act of war?
Interestingly a presumably Iranian hacker claimed the attack and stated that his motivation was political: revenge for the Srebrenica massacre the part the Dutch government played in it. It seems then that destabilizing the Dutch government was not just a side-effect, but a direct target of the attack. One can wonder how convincing is it that such a young person would successfully perform a hack on a major certificate authority all by himself. Especially when one hypothesizes about government involvement and if one takes into account that the target of the attack was announced to be the Dutch government, then this attack can potentially be interpreted as an act of war.
The following quote argues against jumping to such conclusions:
“Security expert Robert Graham, who’s swapped e-mails with Ich Sun and ultimately confirmed that he was indeed the one who pulled off the Comodo hack, thinks otherwise. He accuses Comodo and reporters who have covered this story of jumping to conclusions about the Iran connection. “We make the assumption that anyone who supports the government there works for the government and that’s just not true,” said Graham, CEO of Errata Security. “My theory is he’s exactly what he says he is. That’s what the evidence points to. There’s no evidence that says he would have to be part of a state-sponsored effort. The attack is not that complex. It’s just what your average pen-tester would do.” source
Interestingly, the later investigation report by Fox-IT ( download link from a Dutch government website showed that “Around 300.000 unique requesting IPs to google.com have been identified. Of these IPs >99% originated from Iran” (p. 8). It turned out that practically all victims of the attack on a Dutch certificate authority where in fact Iranian gmail users. The target then was not the Dutch government after all. The Dutch certificates were used for a massive man-in-the-middle attack on Iranian civilians.
The take-away is that calling something an act of war in the cyber domain is to some extent a matter of interpretation as the relevant actors become increasingly less identifiable. That act of interpretation however has huge potential consequences. In the context of the cited article those consequences are mostly economical for companies whose damages might not be covered by their insurance. But the potential political consequences are the most worrisome. As digital systems become more interwoven with essential infrastructures and with other digital systems, warfare will also become increasingly digital. In accordance, those with the knowledge and capabilities to work and influence computer systems de facto have political power. And when the relevant parties of “warlike” acts in the digital domain cannot be identified anymore as government parties, the distinction between war and terrorism blurs, as the distinction heavily relies on the violence of the former being warranted by a nation, whereas that of the latter is against a state or nation.
This made me remember a reflection of Derrida on how technoscience blurs the rigorous distinction between war and terrorism, in a book I have read about five years ago (it made an impression apparently). I looked it up again. The following passage is from the book “Philosophy in a Time of Terror” (2003) by Giovanna Borradori. In the words of Jacques Derrida:
No geography, no “territorial” determination, is thus pertinent any longer for locating the seat of these new technolgies of transmission or aggression. To say it all too quickly and in passing, to amplify and clarify just a bit what I said earlier about an absolute threat whose origin is anonymous and not related to any state, such “terrorist” attacks already no longer need planes, bombs, or kamikazes: it is enough to infiltrate a strategically important computer system and introduce a virus or some other disruptive element to paralyze the economic, military, and political resources of an entire country or continent. And this can be attempted from just about anywhere on earth, at very little expense and with minimal means. The relationship between earth, terra, territory, and terror has changed, and it is necessary to know that this is because of knowledge, that is, because of technoscience. It is technoscience that blurs the distinction between war and terrorism. (p. 101)
Digital portraits
My friend Rits did me a big favor by making some digital portraits of me. His website is currently in quarantine because he was too late with re-registering his domain name, but if you read this post after sunday 17 March you can check out his web site. While doing me a favour, Rits made sure that he enjoyed himself.

See right for a first proof of concept. After seeing this sketch, I had complete faith in the end result.
You can see the final results on my home page. If you feel adventurous, make sure to switch to the dark theme by clicking on the switch button on top for an amazing GIF. The normal portrait did not fit with the dark theme, so we decided it was best to design another portrait for that. We couldn’t quite figure out how to avoid creepy hollow eyes with high contrast against a dark background. After long deliberation, we came up with a creative solution…
Here are some of the other variations Rits proposed before we settled on the final portraits:


Two notes on the original Google paper
A few days ago Djoerd Hiemstra gave a guest lecture on estimating the size of big data problems, within the context of a Big Data course I am currently following. As a preparation, we read the paper of Sergey Brin and Lawrence Page from 1998 where they introduced the anatomy of their search engine called “Google”. We did so in particular because it is interesting to compare their estimations on the size and scalability of Google with the colossus it has become today.
However, at the end of his guest lecture he pointed out two “fun facts” that I’d like to quickly share here.
The first point is awkward and warrants a discussion of how valuable it is to be accepted at an academic conference. Despite being rejected, the contents of the paper and the company that followed from it completely reshaped the social reality of many.
The second point is also interesting and has an ironic note to it, given that we now know the direction in which Google headed. Follow the link above to read it for yourself (the paper is freely accessible), but here are two fragments:
Out of historical experience, the authors
expect that advertising funded search machines will be inherently biased towards the advertisers and away from the needs of the consumers (p. 18).
And:
In general, it could be argued from the consumer point of view that the better the search engine is, the fewer advertisements will be needed for the consumer to find what they want. This of course erodes the advertising supported business model of the existing search engines. However, there will always be money from advertisers who want a customer to switch products, or have something that is genuinely new. But we believe the issue of advertising causes enough mixed incentives that it is crucial to have a competitive search engine that is transparent and in the academic realm. (p. 18).
Morton's Perverse Holism - A Twelve-step program
A year ago I attended a lecture by Timothy Morton. I had not seriously read anything of Morton except a quite extravagant paper called “From modernity to the Anthropocene: ecology and art in the age of asymmetry”, which flamboyantly combined Hegel, art and ecology in a manner I do not recall. The lecture was equally flamboyant, and can perhaps best be described as a confused rant that simultaneously felt very genuine and personal. The lecture can be listened to integrally. Some time after the lecture, I watched an interview of Morton with his publisher, in which in particular his conception of holism struck me as refreshing.
The most summary description of holism undoubtedly is the phrase: “The whole is greater than the sum of its parts.” It concerns the emergence of a synergetic phenomenon that cannot be properly understood by only referring to its constituent parts. In other words, it concerns a phenomenon that is not reducible. In philosophy I often dealt with this idea in my studies of hermeneutical phenomenology, but in Artificial Intelligence it is equally relevant for understanding the emergence of intelligence from the complex interactions of smaller units (e.g. neurons) that are in themselves not intelligent. But although this fundamental idea is common to many different disciplines, this connection does not imply a simple consensus but instead a common question mark. So let us not assume the meaning of holism is self-evident: it implies a complete mereology, the metaphysics of the ongoing dialogue between wholes and parts.
In the following I quickly want to offer a twelve-step program of Morton’s “perverse” conception of holism from the interview and the lecture a year ago, as far as I can remember it.
That’s my recap of Morton’s argumentation related to holism, condensed in a twelve-step program. At this point, I am mostly left with questions, which might be because I’ve never read any of Morton’s books. In any case, I deemed a twelve-step program appropriate for a philosopher that seemed to be in the middle of a drug-induced manic episode and frantically kept insisting he’s a bad philosopher (or not one at all).
Security and privacy: some key concepts
Discussions about privacy- and security issues are in the news daily, related to some scandal, data leaks, new regulations (GDPR), increased surveillance in response to terrorism, etc. But what do these concepts of privacy and security actually mean, and how do they relate to each other? Everyone probably has some intuitive notion of these concepts, but on a closer look, they are more complex than one would expect. Discussions about privacy and security should begin with: what privacy, what security? These questions, despite their perhaps “dry” conceptual nature, are important for anyone interested in what is at stake in the privacy- and security-related discussions going on right now. In fact it is also important for those that do not share this interest, because the results of these discussions will affect them nevertheless. The goal of this blog post is to provide some pointers, distinctions, and questions; not answers. I have only relatively recently begun to engage with these topics myself and by writing this post I hope to test and develop my current understanding of the topic, which is very much in progress, perhaps even infantile.
Security and privacy ¶
A first distinction need to be made between “security” and “privacy”. Security relates to the regulation of access to some system. In a digital context these would be computer systems, from the servers of a secret agency to the personal computer of your grandma, if she has one. This is not the same as privacy, which can mean many things but in general essentially relates to persons or individuals. So a first basic distinction perhaps is that digital security pertains to various aspects of a communication channel itself, whereas privacy relates to the individuals involved in this communicative process, mediated by some technology.
Nevertheless security is a relevant topic for privacy. For a significant part, the security of communication between persons is a precondition for guaranteeing privacy. But it surely is not a sufficient condition. For example, with good cryptography one can make sure that third parties do not read the content of your communications. But the very fact of your communication may contain information that intrudes your privacy, e.g. it contains information about who you know, or about your location (e.g. where you work or live); which is information that you perhaps did not intend to share and which might be very sensitive. In that sense, cryptography, or computer security in general, solves problems only by moving them to another domain.
In some discussions security and privacy seem to exclude each other. Acts of terrorism never fail to spark debate on whether to give surveillance agencies more power to snoop on civilians, i.e. reduce their privacy, under the banner of increasing security against people with malicious intent. In that sense, the question becomes: security or privacy? But what we need is security and privacy.
In the following I want to map out some useful concepts related to security and privacy that I encountered so far when reading on this topic.
Security ¶
Considered naively, computer security can be easily thought of as some monolith stating “here and no further”. But in reality, security is a fluid concept that should be understood relative to an attacker with a given amount of resources. At the border case, absolute security requires resistance against an attacker with infinite resources. The notion of such an “absolute” security is meaningless, as it arguably requires a complete blockage of access. However, the point of securing real systems is not to block access as such, but to regulate access to whatever assets or capabilities that system has. That is, it needs to allow access, but only to the right people.
So the concept of security only makes sense against the backdrop of a potential attacker. But on top of that, whether something can be called secure depends on the context of the system, its purpose and the needs of its users. The security goals of various systems might differ, and the way in which we call system A secure can be different from the way we call system B secure. Let’s look at some examples of different security goals in different contexts. In order for critical systems in hospitals to be secure, their availability needs to be guaranteed at all times. If in that same hospital medical information is stored about you, its confidentiality is strictly required. Now imagine you need a blood transfusion, but someone changed the information on your blood type in the medical system, i.e. its integrity has been breached, with potential lethal consequences. In another example, to reliably transfer money using online banking, confidentiality is less of an issue than the authenticity of the sender, bank, and recipient. E.g. when you transfer money to the bank you want to be sure you do not in fact transfer money to a criminal “man in the middle”. More easily overlooked is the principle of non-repudiation: after you have transferred your money, you cannot later deny you did so.
You can think of many contexts where one security goal is absolutely required, whereas another may be less relevant. In other words, in different contexts “security” means different things, depending on the relative importance of the aforementioned security goals: confidentiality, integrity, authenticity, non-repudiation, availability. The goal of this section was merely to transmit the basic intuition that the concept of security is less univocal than it may seem, and provide some first differentiations.
Privacy ¶
But even if the communication is secure, what information do you give to these systems? How are they stored, and how are they used? Do you keep any control over this? Imagine the aforementioned hospital leaking your medical information to your health insurance: you can bet your fees to go up. A hospital doing so would be an extreme case. But now imagine a free fitness app doing the same after storing information about your health and condition (e.g. hearth rates during running, or weight etc.). The people installing that fitness app, after accepting the “terms and conditions” that they quite reasonably did not read, might potentially sell their data for such usage without being aware of it. So although that app would be “free” in the sense of gratis, it does come at a cost.
Privacy as a concept seems tightly entwined with the idea of an individual. The above example concerns sensitive information about individuals, and indeed most discussions about privacy nowadays concern the use of personal data by various companies and the control individuals keep over that use. This sense of privacy can be traced back to Westin’s definition of privacy in 1967 as “the claim of individuals […] to determine for themselves when, how, and to what extent information about them is communicated to others.” Privacy in these contemporary discussions thus means something like “control over your data”, and is a unique issue that occurs in the digital era. It is interesting that most people would probably not bother to hide their shopping cart when doing groceries, whereas knowledge of your online shopping behavior more quickly becomes a privacy issue. Privacy can thus mean something different online and offline. Simultaneously, the integration of digital devices into our lives increasingly blurs the line between online and offline, and also between public and private.
Perhaps this difference has something to do with a perceived sense of anonymity you have when sitting at home browsing the internet. In the domestic sphere of the house, you act from within a relatively protected and secluded situation, which suggests privacy in the “old fashioned” sense of “being left alone” (as defined by Warren and Brandeis already in 1890).
This situation shows a clear incongruency between different conceptions of privacy: you are indeed left alone, but simultaneously you are not in full control of your own personal data, and moreover this data is used to manipulate you without you realizing it, for example in the results you see for internet searches (cf. the “filter bubble”), or in targeted advertising. You do not only lose control over the information you expose to the internet, but also lose control over what information is shown to you. Perhaps the net is neutral, but the information you “find” (or: is presented to you), certainly is not. The famous meme “on the internet, no one knows you’re a dog”, was valid years back, but over time changed into the description of a comfortable illusion.

It depends on your definition of privacy whether it is violated or not in the scenario I just sketched. But most interestingly, what it shows is that the digital era effectively initiated a transformation in the concept of privacy that is occurring as we speak. A digital-savvy portion of the population is constantly sounding alarms left and right about privacy issues, whereas others do not only not experience a breach of privacy, but also think the discussion is nonsensical because they “have nothing to hide”.
On the way to privacy ¶
These initial considerations barely scratch the surface. I want to think more about privacy in the coming months in all its nuance and complications. For example, what is the relationship between privacy and intimacy both in the “analogue” and digital domain? What are the links between related concepts such as secrecy or confidentiality, which are all partly overlapping but not the same? How does privacy relate to an individual’s freedom? It is also possible to develop perspectives that rely less on the individual, as I did here. How does privacy take shape in negotiations between individuals in communities, i.e. how is privacy also essentially a social process? And how can such a multi-faceted dynamic concept be adequately represented in law, which seems primarily concerned with regulating data processes?
A philosophical discussion that takes a step back before being activistic is relevant, because how can we really guarantee privacy in the applications we implement, or protect it by law, without having a clear view of what it is? That is not a plea for passivity, as it is unreasonable to expect of anything worthwhile that it can be captured in a few clear concepts. Neither does it invalidate raising your voice before being completely informed, because a certain degree of “conceptual entropy” (trying out a new term here) is unavoidable in a debate that is very much alive and in progress. Instead, I would say that conceptual reflections can contribute to informed action, which in my opinion always includes expressions of doubt rather than offering false certainties. A bit of reflection is needed to be a successful user of the internet, consciously shaping our pluralistic digital identities in all the systems we interact with, rather then becoming its victim.