Object Orientation: Observer Pattern
The observer pattern is a simple yet quintessential design pattern in object oriented programming. As programs become larger, objects multiply quickly, as do the interactions between them. For example, a class instance can be contained as an attribute in another class (composition), or be used by some method in another class (association). Sometimes these class relations are very simple and can be used without a second thought. But let’s assume you have some class containing mutable information (the “subject” class) that is potentially relevant to a larger amount of other classes that observe the subject class. Rather than constantly spamming the subject class to ask whether its information has changed, a lazy and efficient method is preferred: let the subject class keep track of all classes requiring its information and notify them that a change has been made.
Let’s further assume that although we currently have some classes using this information, there could be more or less other observing classes in the future that we want to add. We could of course directly have the subject class contain instances on all observing classes and call methods on all these observers–a direct coupling between the subject and all its observers–but this makes the subject class more complicated than necessary and harder to maintain, as it needs to know about many different objects. This is where the observer pattern comes in. Rather than using this direct coupling to code the one-to-many dependency, we only require the subject class to inform its observers when a change to it is made, without having to specify what to do based on this change. The latter is best delegated to all the different observing classes themselves. Let’s write up a quick and light-hearted example.
As I write this, the Nijmeegse Vierdaagse (the biggest walking event in the world) is going on, and alcohol flows freely through the streets. But of course, not everyone has a healthy relationship with alcohol. After drinking for seven days straight, a not to be specified person realizes he or she might have a problem and decides to see a therapist who starts to observe this person’s behavior.
First, we define the alcoholic:
import java.util.Observable;
import java.util.Observer;
public class Alcoholic extends Observable {
private int beersDrank;
private String name;
public Alcoholic(String name, Observer therapist){
beersDrank=0;
this.name=name;
addObserver(therapist);
}
public void drinkBeer(){
beersDrank++;
setChanged();
notifyObservers();
}
public int getBeersDrank(){
return beersDrank;
}
public String getName(){
return name;
}
}
We are speaking here of the cheap kind of alcoholic that only drinks beers. An alcoholic has some name that the therapist can ask for with a getter. Moreover, we keep track of how much beers the alcoholic drank. The Observer pattern is natively implemented in Java, so to use it we import the Observable class and extend it. Within the Observer pattern, this alcoholic is defined as the observable “subject” class. As said before, it only needs to keep track of its observers so it can notify when a relevant change has been made. In this case, we add a Therapist as an observer with addObserver(new Therapist()). A change to the internals of the alcoholic is made every time a beer is drank (poor liver), so that is the situation in which we notify the observers with notifyObservers(). Now we only need to define the observing Therapist:
import java.util.Observer;
public class Therapist implements Observer {
int beersObserved;
public Therapist(){
beersObserved=0;
}
@Override
public void update(Observable o, Object arg) {
if (o.getClass()==Alcoholic.class && o !=null){
Alcoholic aa = (Alcoholic) o;
beersObserved++;
System.out.println("Therapist says: " + aa.getName() + " you already had " + aa.getBeersDrank() + " beers. That's enough!");
}
}
public int getBeersObserved(){
return beersObserved;
}
}
The therapist can observe multiple alcoholics in parallel and keeps track of the total amount of beers it has observed. Whenever an observed alcoholic drinks a beer and notifies its observer (the therapist in this case), the therapist knows it has to update its knowledge of the observed class. The Observer interface provides the update function that is called whenever the alcoholic calls the notifyObservers() function. It is possible that the therapist also observes other kinds of patients that are not alcoholics, so we need to distinguish what the therapist does for what kind of patient. In our case, we only care about alcoholics, but to be complete we still check the class of the object we observe to take the appropriate action. In this case we simply give the alcoholic a small preach every time he or she has a beer (probably not so effective, but hey I’m not a therapist myself).
Let’s test our code:
public static void main(String[] args) {
Therapist therapist = new Therapist();
Alcoholic student1 = new Alcoholic("Student1",therapist);
Alcoholic student2 = new Alcoholic("Student2",therapist);
student1.drinkBeer();
student2.drinkBeer();
student1.drinkBeer();
student1.drinkBeer();
student2.drinkBeer();
System.out.println("The therapist counted " + therapist.getBeersObserved()+" beers.");
}
Which gives the output:
Therapist says: Student1 you already had 1 beers. That's enough!
Therapist says: Student2 you already had 1 beers. That's enough!
Therapist says: Student1 you already had 2 beers. That's enough!
Therapist says: Student1 you already had 3 beers. That's enough!
Therapist says: Student2 you already had 2 beers. That's enough!
The therapist counted 5 beers.
Although the Observer pattern is in essence simple, its importance cannot be overstated. It is for example very important in the MVC-architecture that advocates a separation between model, view, and controller. The controller can make adjustments to the model, containing the program logic, and various “view” classes designed to display the model need to be informed about updates in the model effectively without becoming entangled with the model. The observer pattern takes care of just that.
Object Orientation: Strategy Pattern
In object-oriented programming classes tend to multiply quickly. Luckily, some design patterns are available to solve commonly occurring issues. In this post I want to quickly illustrate the strategy pattern with an easy example written in Java. To make it intuitively clear why this pattern is called the ‘strategy’ pattern, let’s sketch a situation in which the application of different strategies is important: a game.
Without getting lost in the philosophical details of what constitutes a game, we can safely assume a game at least needs players. So let’s make a Player class. We want a player to have a name, a team, and a game strategy:
public class Player {
private String name;
private Team team;
private Strategy strategy;
public Player(String name, Team team, Strategy strategy){
this.name=name;
this.team=team;
this.strategy=strategy;
}
public String yell(){
return this.name+" yells: "+team.yell();
}
public void changeTeam(){
this.team=team.other();
}
public String getName(){
return this.name;
}
public Team getTeam(){
return this.team;
}
public String getStrategy() {
return this.name+"'s strategy: "+this.strategy.sayStrategy();
}
public void setStrategy(Strategy strategy) {
this.strategy=strategy;
}
}
This class definition requires us to define at least two other classes, one for defining what a team is and another for determining the player strategy. Let us assume that for this particular imaginary game (we haven’t defined any actual rules), there are only two teams per game: a blue and a red team. Since blue and red are the only possible team instances, we can use an enumeration type. For some reason each team has an incredibly silly yell:
public enum Team {
RED,BLUE;
public String yell(){
switch (this) {
case RED: return "We are the red devils!";
case BLUE: return "Blue is the color of righteousness!";
default: return "";
}
}
}
Now the strategy pattern comes into play. We want each player to potentially have a different game strategy. A naive solution would be to create different player classes. We could have one class called CheatingPlayer and one class called FairPlayer and so on for all potential strategies. However, each of these classes will have the exact same code except for the code defining the strategy. Unnecessary code duplication must always be avoided. If you for example want to change some characteristic of the player, you would have to edit all duplicate code in all these classes. The strategy pattern solves this issue.
As we saw, we have a single Player class that has a Strategy as an attribute, but other than this we do not specify yet what particular strategy. The player could have whatever strategy, the only obligation we make now is that it has one. The solution is to make Strategy an interface defining what obligations each particular strategy should fulfill. Normally a strategy should have some influence on the player’s behavior in the game, but since we don’t program the game itself to keep it simple, we just want players to state their strategy when asked:
public interface Strategy {
public String sayStrategy();
}
Each particular strategy has to define which String this function returns. For simplicity, let’s assume for now there are two particular strategies implementing the Strategy interface, one where we intend to cheat, and one where we will play fairly (whatever that means):
public class CheatingStrategy implements Strategy {
@Override
public String sayStrategy() {
return "Sedating the enemy team with horse tranquilizer";
}
}
public class FairStrategy implements Strategy {
@Override
public String sayStrategy() {
return "Shaking hands, wishing the opponent good luck (because they need it)";
}
}
We can create as many strategies as we see fit, and our problem is solved: each player can have a different strategy without having to define multiple player classes with duplicate code. Let’s see how it works:
public class StrategyPattern {
public static void main(String[] args) {
Strategy cheating = new CheatingStrategy();
Strategy fair = new FairStrategy();
Player Edwin = new Player("Edwin",Team.BLUE,fair);
Player Diablo = new Player("Diablo",Team.RED,cheating);
System.out.println(Edwin.yell());
System.out.println(Diablo.yell());
System.out.println(Edwin.getStrategy());
System.out.println(Diablo.getStrategy());
}
}
The console output is:
Edwin yells: Blue is the color of righteousness!
Diablo yells: We are the red devils!
Edwin’s strategy: Shaking hands, wishing the opponent good luck (because they need it)
Diablo’s strategy: Sedating the enemy team with horse tranquilizer
Calculating pi with Monte Carlo simulation
I came across Monte Carlo sampling in a class on Bayesian statistics, where a Markov Chain Monte Carlo (MCMC) sampler was used to approximate probability distributions that were otherwise hard to calculate due to nasty integrals. This posts illustrates the basic idea of Monte Carlo sampling, by using it to approximate the number $\pi$.
The basic procedure is as follows:
- Take a circle with radius $r$
- The area of the circle is $\pi r^2$
- Draw a containing square which then has area $(2r)^2=4r^2$.
- Sample points randomly within the square, and count how many fall within the circle
- Calculate the proportion of samples within the circle to the total amount of samples, and multiply by 4 to approximate $\pi$.
How does it work? ¶
Now we ask: what is the probability that any randomly sampled point within the square lands in the circle? This probability is the proportion of the area of the circle with respect to the total area (i.e. that of the square). We don’t want the sampling itself to influence the results, so having a uniform distribution to sample from is important.
Thus the probability that a randomly generated point lands in the circle is: $$\frac{\pi r^2}{4r^2} = \frac{\pi}{4}$$
This means that if we accurately approach the probability of a random point landing in the circle, we end up with a fourth of $\pi$. The law of large numbers states that if we repeat this experiment often enough the average of the results approaches the expected value, which is a fourth of $\pi$ in this case. It is no wonder that this method is called Monte Carlo: you might win a few games, but on average the casino always wins in the long run.
We can generate points with x and y coordinates uniformly sampled between -1 and 1. This effectively amounts to saying that for the circle we use a radius of 1, centered in (0,0). Now we need to determine a test for whether any given point lies in the circle. Given a sampled point, we can reconstruct if it lies on a circle with a radius smaller than 1. The radius is obtained with the “hypot” function, i.e. $\sqrt{x^2+y^2}$. If the reconstructed radius is smaller than the radius of our circle, we know it must lie within the circle we defined with radius 1. Otherwise, we know it is a point that only lies within the containing square, but not in the circle.
To get the probability we are interested in, we only have to divide the number of sampled points within the square by the total amount of samples. To get an approximation of $\pi$, we multiply this probability with 4.
Python script ¶
This is the python 3 script I wrote, so you can play around with the parameters yourself. The code for a simple histogram plot is also included, but you should delete this if you don’t have the matplotlib package (and don’t want to install it).
import random
import math
import matplotlib.pyplot as plt
radius=1
samples=10**6
iterations=100
countdown=iterations+1
estimations=[]
for i in range(iterations):
sample_inside=0
for sample in range(1,samples+1):
hyp_r = math.hypot(random.uniform(-radius,radius),random.uniform(-radius,radius))
if hyp_r < radius: sample_inside +=1
countdown-=1
print(countdown)
estimations.append(4.0 * sample_inside / sample)
print("Approximation of pi: ", sum(estimations)/float(iterations))
bins=int(iterations/2)
plt.hist(estimations, bins=bins,histtype='step')
plt.savefig("pi-plot.png")Sampling and Plots ¶
Another question is how much samples we need: a lot. Without working out the mathematics, some quick and dirty testing shows that in order to get only one decimal accuracy we already need at least 10.000 samples. Unfortunately, to get more accuracy, we need relatively more and more samples, since the rate of convergence is the inverse of the square root of the number of samples N. In simple words: the higher the number of samples we take, the slower the convergence.
With a million samples, we can approximate the first two decimals well, but for the third decimals we already start getting into trouble. On top of that, the approximation becomes slow… Instead of straightforwardly pumping up the number of samples taken to increase the accuracy, I tried out another strategy. Instead of running a simulation with for example 100 million samples, I tried running 100 simulations with a million samples, and taking the average of those for the final approximation. In this manner we can create a confidence interval and say something about how reliable our estimate is. Since all samples are independent and concern a stochastic variable, the central limit theorem applies. In other words: if we have enough approximations, these approximations themselves will follow a normal distribution. I have an ongoing discussion with some friends about the benefit of this method, compared to running one bigger simulation. My current position is that with taking the mean over multiple approximations (which are themselves means over a million samples), we have a lower maximum precision than a single run with the same amount of total samples, but effectively get a better estimate because the result is more reliable.
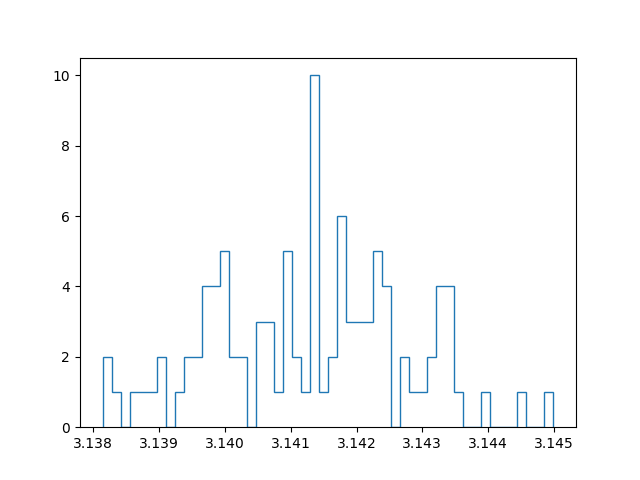
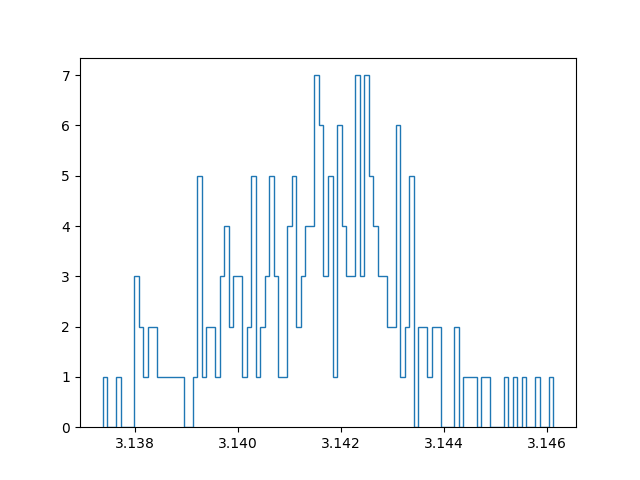
Below are plots using a million samples and 100 and 200 iterations respectively. We indeed see that the means of the iterations crudely follow a normal distribution.
Course overview
I drafted up a preliminary list of the courses I followed at university. It can be found here, and I also added a link to it in the “about” section of this blog.

Terminal sharing with tmux
For a while now I have been wondering how to share my terminal with others, for two reasons. First of all, I was intrigued by the idea of remote partner programming. For practically all of my study projects I engage in partner programming, which usually means I work with someone on the same machine. One small complication however is that I almost exclusively work together with Germans, who inconveniently use a different keyboard layout. Most special signs (such as brackets, which are absolutely necessary in programming) are all over the place. Typing on those keyboards is a frustrating experience, but even without taking that into account, is it preferable to work in a familiar environment on your own machine.
So what if we can work together in the same virtual environment while simultaneously having the comfort of looking at our own screens? An obvious drawback of sharing a terminal session is that we are locked in the terminal: no graphical applications, no fancy IDE’s. However, lately I have been using vim more intensively, and this drawback perhaps motivates me to try and turn vim into a nice IDE that is usable in any terminal. The chances that I will actually use this are probably fairly slim, but I like the idea that I could.
A second and somewhat trivial reason for me to share my terminal, is that a friend recommended a game for in the terminal which I wanted to try out. He asked me if he could watch along as I played, to help me get started (the game is called ‘cataclysm’ by the way). What follows is a guide how to share a terminal session with minimal means: only tmux is required. I am assuming ssh is properly and safely set up. Consider reading this post.
Basic idea ¶
This basic idea gives another user access to your system. Make sure to take the necessary precautions. For example, make a separate user in your system with restricted rights for pair programming. I discuss this option below.
On your host/server, create a tmux session and attach to it:
tmux new -s shared
tmux attach -t shared
Connect to the host over ssh from another pc:
ssh -p port address
Show current tmux clients running on the server, and attach to the existing session.
tmux ls
tmux attach -t shared
You are now both working in the same session. Changes can be made by both partners and are shown in real time.
Assign each partner a separate independent window ¶
Only the last step differs. Instead of joining the same sessions, the user connecting to the tmux server makes a new session and assigns it to the same window group as the session we just called shared.
tmux new -s newsessionname -t shared
Or achieve the same effect with:
tmux new-session -t 'original session name'
If you now run " tmux -ls “, a short-hand for tmux list-sessions, we see that we have two sessions belonging to the same group. If we only have one window, we do not notice any difference with a setup not sharing a group. However, if we make a new window with “Control-b c”, and then select it with “Control-b windownumber”, we are able to switch to another window where we do not share a cursor with our programming partner. However, at any time we can come back to the original window, or conversely our partner can come visit our window to cooperate.
You can now take turns writing code, conquering Zeit-Raum.
Creating a guest user for pair programming ¶
If you do not use a server but your machine to ssh into, then you probably want to prevent someone gaining full access to your files. One option is to create a separate user account on your system for guests, that has restricted permissions and does not have access to your precious home folder, nor permission to change any essential files. Let’s say we make a user called ‘pair’:
useradd -m pair
This creates a user ‘pair’ on your system. The -m flag creates a home directory for this user. I assume here that by default a new user does not have sudo rights, but make sure to double check this. You also want to set a password for this user:
passwd pair
Once we have the user set up as we want to, we have another challenge. When we run a tmux server on our own account, that server is not visible to the new user ‘pair’ when we check the available sessions with “tmux -ls”, because that only shows the sessions running of the current user. Somehow, we need a way to let tmux communicate between users. We can achieve this by opening a socket:
tmux -S /tmp/socket
As far as I’m currently aware of, this creates a temporary soft link through which other users can link to the tmux session. I placed it in the /tmp/ folder because our newly created ‘pair’ user can read that file. However, the ‘pair’ user does not yet have the right permissions. A quick way to fix this is to run:
chmod 777 /tmp/socket
Another tactic could be to create a custom group with the right permissions, to which only your main account and the guest account belong. The ‘pair’ user can now connect to your session through the socket using:
tmux -S /tmp/socket attach
Note however that if you let the guest user connect through the socket to your main user, that user gains access to the terminal as you, which means: it gets the permissions we denied it in the first place. Since you have sudo rights, a safer option would instead be to create the session on the ‘pair’ account and join that session. I guess everyone has to make the decision to what extent the programming partner is trusted not to engage in “funny business” on your home account. As long as the guest does not know your sudo password, the risks are still somewhat limited, but the guest does have access to your home folder, which is something to consider. I do not have actual working experience with both setups, and am not aware of the usual standards for remote pair programming, so perhaps I update this post later. I assume the standard is to use a server in the cloud, which circumvents all problems I pose here in the first place. You also need it if you are not in the same network and you do not want to expose your pc directly to the internet. As of now, I do not have such a server myself though.
If your intent is not pair programming, but only sharing your terminal, then there is a solution though. If you force a guest user to enter the tmux session in read-only mode immediately upon connecting over ssh, then there is no way to exit the tmux session and gain access to your home account. Of course the guest can decide to detach from the tmux session, but in that case is simply returned to its own home folder. So unless a malicious user detaches, finds the socket to connect, and also knows your sudo password, you should be fine in this case.
To enter in read-only mode, attach the -r flag:
tmux -S /tmp/socket attach -r
Mixing it all up ¶
Let’s apply the previous and combine it with the possibility of having independent windows. Run:
tmux -S /tmp/socket new-session -t sessionnameorid
Making the guest automatically connect to the socket session ¶
Since we made the guest account ‘pair’ solely for sharing our terminal, it makes sense to let anyone who connects to it over ssh automatically connect to our tmux session through the designated socket. To achieve this, we can edit our /etc/ssh/sshd_config file (solution found here). Add the following for pair programming:
Match User pair
ForceCommand /usr/local/bin/tmux -S /tmp/socket new-session -t 0
We assume here the session we created over the socket is named “0”, which is the session id if you don’t give it a name (which I did not). Again, if we always want the guest user to connect in read-only mode for simple terminal screen sharing, instead enter:
Match User pair
ForceCommand /usr/local/bin/tmux -S /tmp/socket attach -t 0 -r
Have fun!